| 10 / 21 -- Introduction |
|---|
|
- Quelques travaux
-
Cooperative backup scheme (2002, Rice Univ.),
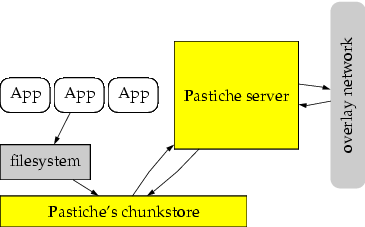
Pastiche/Samsara (2002, MIT), PeerStore (2004, TU München),
Venti-DHash (2003, MIT), ABS (2004, MIT), etc.
-
Accent sur les incitations à la
contribution et la résistance aux malveillances
-
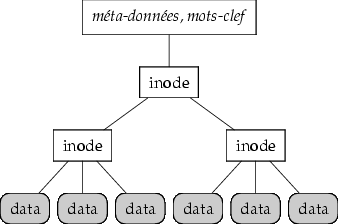
Également élimination des redondances,
performances de la sauvegarde et récupération
- Des techniques issues des réseaux pair à
pair
-
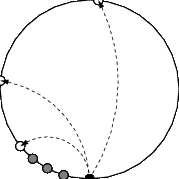
Routage entre pairs et découverte décentralisée
de pairs
-
Chiffrement convergent
-
Indexation du contenu
|
|
 )
) )
)