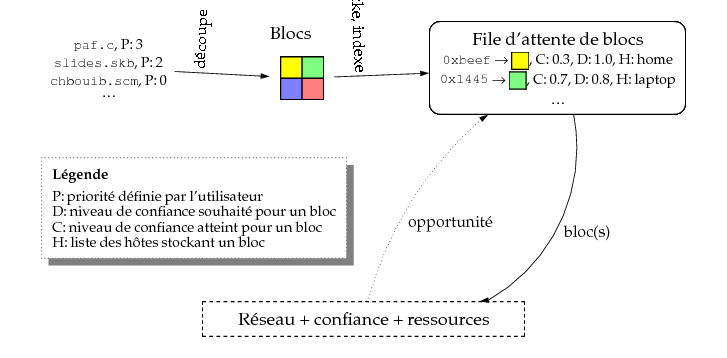
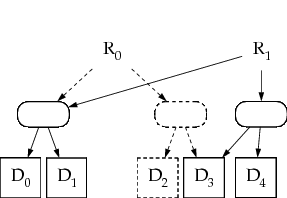
- Fichier découpé en blocs : D0 à Dn
- Création de blocs d'indexes intermédiaires
- L'index de la racine (R0) suffit pour récupérer tous les blocs
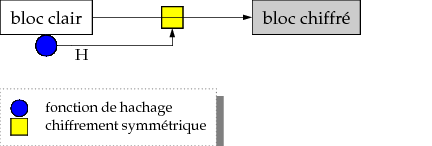
- chiffrer les blocs individuellement ⇒ permet de conserver la relation d'égalité entre blocs
- une possibilité : chiffrement convergent
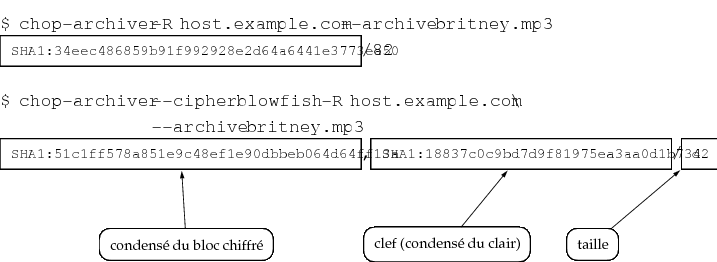
- Répertoire d'indexes : contient une liste d'associations nom/clef
- Chaîne d'index : contient l'index de l'élément précédent dans la chaîne et une date
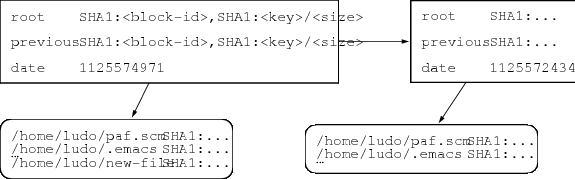
(Déjà vu à Rennes en mai.)