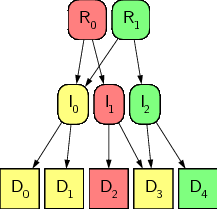
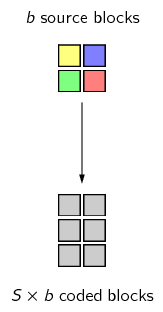
- Costly and Complex Backup
-
only intermittent access
to one's desktop machine
-
potentially costly communications
(e.g., GPRS, UMTS)
- Our Approach: Cooperative
Backup
- (illustrated)
-
leverage encounters, opportunistically
-
high throughput, low energetic cost (Wifi, Bluetooth, etc.)
-
leverage excess resources
-
variety of independent failure
modes
-
hopefully self-managed
mechanism
|  |